

این مقاله، که بخشی از مجموعه مقالات معرفی زیرساختهای کلیدی هوش مصنوعی جهان است، بر تحلیل معماری انحصاری گوگل، یعنی Google TPU Pods، تمرکز دارد.
تغییر پارادایم از محاسبات سنتی سرور-مبنا (Server-based) به هوش مصنوعی مبتنی بر شتابدهندهها (Accelerator-based)، یک تحول عمیق در معماری زیرساخت دیجیتال ایجاد کرده است. مراکز داده هوش مصنوعی (AI Data Centers)، برخلاف مراکز داده سنتی یا حتی مراکز محاسباتی با کارایی بالا (HPC)، صرفاً فضایی برای میزبانی سرورها نیستند؛ بلکه "کارخانههای هوش مصنوعی" (AI Factories) کاملاً تخصصی و بهینهسازیشدهاند.
پیدایش واحدهای پردازش تنسور (TPU) توسط گوگل، واکنشی مستقیم به نیازهای محاسباتی در حال گسترش خدمات داخلی این شرکت (مانند Search، YouTube، و مدلهای زبان بزرگ DeepMind) بود.
TPUها به عنوان مدارهای مجتمع با کاربرد خاص (ASIC) طراحی شدهاند که منحصراً برای تسریع حجم کاری یادگیری ماشین بهینهسازی شدهاند. این رویکرد، TPU را از پردازندههای موازی همهمنظوره مانند GPUها متمایز میکند.
تفاوت بنیادین بین TPU و GPU، نه در رقابت برای دستیابی به تعداد بیشتر عملیات ممیز شناور (FLOPs)، بلکه در فلسفه طراحی نهفته است. TPUها با هدف به حداقل رساندن حرکت داده و به حداکثر رساندن کارایی انرژی برای ریاضیات تنسور متراکم ساخته شدند.
این سختافزارهای تخصصی، انعطافپذیری محاسباتی را فدای کارایی مطلق در اجرای شبکههای عصبی میکنند، در حالی که GPUها باید به اندازه کافی قابل برنامهریزی باقی بمانند تا از رندر گرافیکی گرفته تا شبیهسازیهای HPC را مدیریت کنند.
این تخصصیسازی به گوگل این امکان را میدهد تا به ۱۰ برابر کارایی Total Cost of Ownership (TCO) نسبت به GPUها برای حجم کاری هدفمند هوش مصنوعی دست یابد.
مقیاس ابررایانشی در گوگل از طریق مفهوم "TPU Pod" تعریف میشود. یک Pod مجموعهای از تراشههای TPU است که از طریق یک اتصال داخلی سفارشی (ICI) به یکدیگر مرتبط شده و به عنوان یک شتابدهنده منطقی واحد عمل میکنند.
این اتصال، گلوگاههای تأخیر و پهنای باند موجود در شبکههای سنتی (مانند اترنت یا InfiniBand) را برطرف میکند و عملیات جمعی (collective operations) مانند All-Reduce را بسیار سریعتر اجرا مینماید.
تکامل Podها گواهی بر رشد نمایی در نیازهای هوش مصنوعی است. در حالی که نسلهای اولیه Podها تا ۲۵۶ یا ۱,۰۲۴ تراشه را شامل میشدند ، نسلهای جدیدتر مقیاس بیسابقهای دارند.
به عنوان مثال، گوگل با نسل Ironwood (جدیدترین TPU در دسترس) به Superpodهایی با ۹,۲۱۶ تراشه دست یافته است که توان محاسباتی ۴۲.۵ اگزافلاپس (Exaflops) در دقت FP8 را ارائه میدهند.
این مقیاس عظیم برای آموزش و ارائه مدلهای پیشرو در صنعت مانند Gemini ضروری است. تعهد شرکتهایی چون Anthropic به استقرار بیش از یک میلیون تراشه TPU، که نماینده بیش از یک گیگاوات ظرفیت محاسباتی است، اهمیت زیرساخت TPU را در عصر مدلهای بنیادین نمایان میسازد.
دستیابی به چنین مقیاس و کارایی، صرفاً از طریق یک تراشه قدرتمند امکانپذیر نیست؛ بلکه نتیجه یک همطراحی (Co-Design) جامع در سطح زیرساخت است.
رهبری گوگل در دیتاسنتر هوش مصنوعی نتیجه یکپارچهسازی سه ستون اصلی است: معماری محاسباتی تخصصی (شامل MXU و SparseCore)، شبکه داده با تأخیر بسیار پایین (Inter-Chip Interconnect و Optical Circuit Switching)، و مدیریت حرارتی پیشرفته که اکنون متکی بر خنکسازی مایع مستقیم به تراشه (D2C) است.
این گزارش فنی، جزئیات هر یک از این ستونها را بررسی کرده و نشان میدهد که چگونه همگرایی آنها، استانداردهای جدیدی را برای زیرساخت ابررایانشی هوش مصنوعی تعریف کرده است.

قلب هر تراشه TPU، واحد ضرب ماتریس (MXU) است که بر اساس معماری آرایه سیستولیک عمل میکند. در این طراحی، به جای انتقال مداوم وزنها و فعالسازیها بین واحد محاسباتی و حافظه، وزنها به صورت ثابت درون یک شبکه بزرگ از واحدهای ضرب-جمع (MAC) نگهداری میشوند.
سپس دادههای ورودی به صورت ریتمیک در آرایه جریان مییابند. این جریان داده محلی، از نیاز به دور رفت و برگشت به حافظه جهانی جلوگیری کرده و تنگنای فون نویمان را که در CPUها و تا حدودی GPUها محدودیت ایجاد میکند، مرتفع میسازد.
MXUهای نسلهای اخیر (مانند TPU v6e و TPU7x) شامل آرایههای 256 × 256 هستند که قادرند ۱۶ هزار عملیات ضرب-جمع را در هر چرخه انجام دهند.
در حالی که تمام ضربها از ورودیهای bfloat16 استفاده میکنند، تمام انباشتها (Accumulations) در فرمت عدد FP32 انجام میشوند تا دقت عددی لازم حفظ شود. علاوه بر MXU، TPU v4 به بعد، پردازندههای تخصصی دیگری به نام SparseCore را معرفی کردند.
این هستهها برای رسیدگی به عملیات جاسازی (Embedding) که در سیستمهای توصیهگر، رتبهبندی مدلها و مدلهای زبان بزرگ با واژگان عظیم (مانند Mixture-of-Experts) استفاده میشوند، طراحی شدهاند.
SparseCoreها قادرند ۵ تا ۷ برابر افزایش سرعت را برای مدلهای سنگین Embedding ایجاد کنند، در حالی که تنها ۵ درصد از مساحت دای و بودجه توان تراشه را مصرف میکنند.
این بهینهسازی هدفمند، کارایی را در تمام مراحل چرخه عمر هوش مصنوعی، از آموزش تا استنتاج، تضمین میکند.
مقیاسپذیری TPU Pods وابسته به معماری Inter-Chip Interconnect (ICI) است. گوگل لینکهای دوطرفه پرسرعتی را طراحی کرد که هر تراشه TPU را مستقیماً به چهار همسایه متصل میکند و این امر Podها را قادر میسازد تا به عنوان یک شتابدهنده منطقی واحد عمل کنند. تکامل توپولوژی ICI نشاندهنده نیاز به اتصال قویتر در مقیاسهای فزاینده است:
تراشههای Ironwood (TPU v6) پهنای باند تجمعی دوطرفه ۹.۶ Tbps را از طریق چهار لینک ICI ارائه میدهند که به پهنای باند پیک ۱.۲ TB/s به ازای هر تراشه ترجمه میشود.
این افزایش چشمگیر در اتصال تراشهها، اگرچه عملکرد را تسریع میکند، اما مستقیماً منجر به افزایش چگالی سیمکشی و در نتیجه توان مصرفی و چگالی حرارتی در بردها میشود. این افزایش چگالی حرارتی است که نیاز به استفاده از خنکسازی مایع پیشرفته را توجیه و اجباری میکند.
برای درک عمق پیشرفتهای معماری، جدول زیر مشخصات فنی کلیدی TPU Pods را از نسلهای دارای خنکسازی مایع (v3) تا نسلهای ابرمقیاس (Ironwood) نشان میدهد:
| نسل TPU | توان پیک (BF16) | مقیاس حداکثری Pod | ExaFLOPS Pod (پیک) | توپولوژی ICI | خنکسازی مایع (D2C) | منبع |
|---|---|---|---|---|---|---|
| TPU v3 | ۱۲۳ TFLOPS | ۱,۰۲۴ Chip | ۱۲۶ PetaFLOPS | ۲D Torus | بله | — |
| TPU v4 | ۲۷۵ TFLOPS | ۴,۰۹۶ Chip | ۱.۱ ExaFLOPS | ۳D Mesh | بله | — |
| TPU v5p | ۴۵۹ TFLOPS | ۸,۹۶۰ Chip | حدود ۴.۱ ExaFLOPS | ۳D Torus | بله | — |
| Ironwood | (تا ۴.۶ PFLOPS FP8) | ۹,۲۱۶ Chip | ۴۲.۵ ExaFLOPS (FP8) | ICI پیشرفته | بله | — |

شبکه دیتاسنتر Jupiter، زیربنای مدل ابررایانشی هوش مصنوعی گوگل (AI Hypercomputer) است. Jupiter شبکهای است که امکان ارتباط یکنواخت و دلخواه را بین دهها هزار سرور با پهنای باند صدها Gb/s و تأخیر زیر ۱۰۰ میکروثانیه فراهم میکند.
این زیرساخت مقیاسپذیر، نهتنها خدمات اساسی گوگل (مانند Search و YouTube) را پشتیبانی میکند، بلکه خوشههای عظیم AI را نیز ممکن میسازد.
مقیاسپذیری Jupiter به گونهای است که توانایی اتصال خوشههای بزرگتر از یک Superpod را فراهم میکند. معماری Ironwood میتواند تا ۴۳ Superpod Ironwood را در یک کلاستر واحد مدیریت کند که تقریباً ۴۰۰,۰۰۰ شتابدهنده را شامل میشود و نشاندهنده یک مقیاس محاسباتی بیسابقه است.
این قابلیت مقیاسدهی کلان، حیاتی است تا مدلهای زبان بزرگ (LLMs) بتوانند دادههای خود را در میان صدها هزار تراشه به طور مؤثر به اشتراک بگذارند.
برای دستیابی به چنین مقیاس و کارایی، گوگل Optical Circuit Switching (OCS) را به طور عمیق در معماری Jupiter خود ادغام کرده است.
OCS یک فناوری حیاتی در خوشههای AI است که شبکههای تمامنوری را تشکیل میدهد و جایگزین سوئیچینگهای مبتنی بر بسته سنتی میشود.
OCS با استفاده از فناوریهایی مانند آرایههای نوری MEMS (سیستمهای میکروالکترومکانیکی)، مسیرهای نوری را مستقیماً سوئیچ میکند.
این فرآیند نیاز به تبدیلهای پرهزینه و پرمصرف نوری به الکتریکی به نوری (OEO) و سوئیچهای بسته پرقدرت را از بین میبرد. نتیجه این نوآوری، کاهش قابل توجه در هزینهها و مصرف برق است؛ ترکیب OCS با معماری شبکهسازی تعریف شده توسط نرمافزار (SDN)، در مقایسه با بهترین جایگزینهای شناخته شده، منجر به کاهش ۴۰٪ مصرف برق و ۳۰٪ کاهش هزینه شده است.
این فناوری در TPU v4، کمتر از ۵٪ از کل هزینه و توان سیستم را تشکیل میدهد، در حالی که عملکرد شبکه را به شدت افزایش میدهد. این صرفهجویی برای مقیاسهای گیگاواتی، ضروری است.
یکی از مزایای تحلیلی OCS فراتر از صرفهجویی در انرژی، قابلیت پیکربندی مجدد پویا (Dynamic Reconfigurability) است. TPU v4 اولین ابررایانه در جهان بود که یک OCS قابل پیکربندی مجدد را مستقر کرد.
در خوشههای AI که شامل هزاران تراشه هستند، شکستهای جزئی سختافزاری در طول زمانهای طولانی آموزش اجتنابناپذیر است. سوئیچینگ مداری OCS این امکان را فراهم میکند که به صورت آنی (در زیر ۱۰ نانوثانیه در Ironwood) در اطراف اجزای خراب، مسیریابی مجدد انجام شود.
این انعطافپذیری تضمین میکند که وظایف آموزشی طولانیمدت (مانند آموزش مدل PaLM 540B پارامتری که ۵۰ روز به طول انجامید) بتوانند هزاران پردازنده را برای هفتهها بدون وقفه و با دسترسپذیری بالا مورد استفاده قرار دهند.
علاوه بر این، OCS جداسازی شبکه تمامنوری (Air-gapped) را برای لایههای مختلف یک سوپرکامپیوتر AI چندمستأجره فراهم میسازد که امنیت را برای اشتراکگذاری خوشههای TPU بهبود میبخشد.

انتقال دیتاسنترها به سمت بارهای کاری هوش مصنوعی، چگالی توان رکها را به شدت افزایش داده است. در حالی که چگالی توان رکهای سنتی حدود ۱۵ کیلووات بوده است، خوشههای هوش مصنوعی اکنون این چگالی را به محدوده ۸۰ کیلووات تا ۱۲۰ کیلووات رساندهاند.
این افزایش تصاعدی چگالی، محدودیتهای ترمودینامیکی خنکسازی با هوا را کاملاً پشت سر گذاشته است. گوگل با درک این واقعیت فیزیکی، از نسل TPU v3 استفاده اجباری از خنکسازی مایع مستقیم به تراشه (D2C) را آغاز کرد، زیرا گرمای تولید شده توسط این پردازندههای بسیار قدرتمند از آستانه خنکسازی هوا فراتر رفت.
این استانداردسازی، گوگل را به یک رهبر بلامنازع در زمینه طراحی و استقرار D2C تبدیل کرده است، با تجاربی که نزدیک به یک دهه و چهار نسل از TPU را در بر میگیرد.
خنکسازی مایع، حرارت را تا چهار برابر بهتر از هوا دفع میکند و برای مدیریت چگالی توان بالای ۷۰ کیلووات در هر رک، به یک امر ضروری تبدیل شده است.
خنکسازی مایع D2C، کارایی حرارتی را تا چهار برابر بهتر از هوا فراهم میکند. در سیستمهای TPU، صفحات سرد (Cold Plates) مستقیماً روی قطعات تولید کننده گرما از جمله خود تراشههای TPU و ماژولهای حافظه با پهنای باند بالا (HBM) نصب میشوند.
این صفحات سرد با استفاده از میکرومجراهای (Microchannels) ریز (با ابعاد ۲۷ تا ۱۰۰ میکرون) طراحی شدهاند که به مایع خنککننده (مانند مخلوط آب-گلیکول) اجازه میدهند ۷۰ تا ۷۵ درصد از بار حرارتی رک را مستقیماً در منبع جذب کند.
سیالات خنککننده مورد استفاده شامل مخلوط آب-گلیکول (برای بهبود نقطه انجماد و جلوگیری از خوردگی) یا سیالات دیالکتریک پیشرفته هستند. یک مزیت کلیدی معماری D2C گوگل، توانایی کار با آب گرم است.
سیستمهای مدرن D2C معمولاً با آب ورودی تا دمای 40°C و بازگشتی 50°C عمل میکنند. این دمای بالاتر آب به این معنی است که دیتاسنتر میتواند از سیستمهای خنککننده با راندمان بسیار بالاتر استفاده کند و نیاز به چیلرهای مکانیکی پرمصرف را که بخش قابل توجهی از سربار انرژی را تشکیل میدهند، به شدت کاهش دهد.
اجرای موفقیتآمیز D2C در مقیاس ابررایانشی مستلزم توجه به مهندسی فراتر از عملکرد حرارتی است. گوگل تأکید میکند که طراحی سیستمهای خنککننده مایع برای TPUها باید بر پنج رکن اساسی متمرکز باشد: طراحی برای عملکرد بالا، کیفیت ساخت، قابلیت اطمینان و آپتایم، سرعت استقرار، و قابلیت سرویسدهی عملیاتی.
برای اطمینان از قابلیت سرویسدهی، سیستمهای D2C مدرن با ویژگیهایی مانند کوپلینگهای جداشدنی سریع (Quick-disconnect couplings) برای نگهداری Hot-swappable و سیستمهای تشخیص نشت خودکار که در میلیثانیهها حلقه خنککننده را خاموش میکنند، مهندسی شدهاند.
این ملاحظات عملیاتی برای حفظ دسترسپذیری طولانیمدت هزاران تراشه در یک Pod ضروری هستند. از دیدگاه کارایی، حذف ۷۰ تا ۷۵ درصد از بار حرارتی در منبع، به طور قابل توجهی سربار تسهیلات را کاهش میدهد و به PUE جزئی (Partial PUE) در محدوده ۱.۰۲ تا ۱.۰۳ کمک میکند.
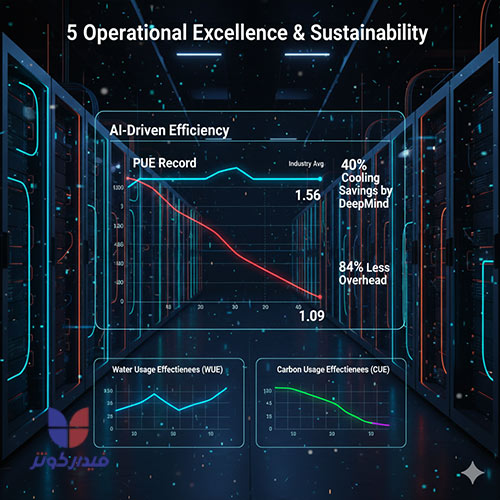
کارایی زیرساخت دیتاسنتر با معیار کارایی مصرف برق (PUE) اندازهگیری میشود که نسبت کل انرژی مصرفی تأسیسات به انرژی مصرفی تجهیزات IT است؛ امتیاز ۱.۰ نشاندهنده کارایی کامل است.
عملکرد گوگل در PUE، به دلیل همافزایی طراحی ASIC (TPU) و معماری خنکسازی مایع D2C، به طور مداوم استانداردهای صنعت را تعیین کرده است. در سال ۲۰۲۴، میانگین سالانه PUE برای ناوگان جهانی دیتاسنترهای گوگل ۱.۰۹ بود.
این رقم به طور قابل توجهی پایینتر از میانگین صنعت (که به طور معمول ۱.۵۶ است) قرار دارد. این تفاوت بدان معناست که دیتاسنترهای گوگل حدود ۸۴ درصد انرژی سربار کمتری برای هر واحد انرژی تجهیزات IT مصرف میکنند.
این کارایی عملیاتی به این دلیل امکانپذیر است که خنکسازی با آب گرم D2C نیاز به مصرف انرژی کمتری برای مدیریت حرارت دارد و در نتیجه سربار را کاهش میدهد.
گوگل یک لایه مدیریت انرژی پیشرفته را در بالای زیرساخت فیزیکی خود مستقر کرده است: بهینهسازی AI-محور خنکسازی که توسط DeepMind توسعه یافته است.
این سیستم کنترل هوشمند، یک چرخه بازخورد "AI برای AI" ایجاد میکند، جایی که مدلهای هوش مصنوعی، زیرساخت فیزیکیای را بهینه میکنند که خود هوش مصنوعی را اجرا میکند. هر پنج دقیقه، AI مبتنی بر ابر، از هزاران حسگر در سیستم خنکسازی دیتاسنتر تصویر میگیرد (شامل دادههایی مانند دما و توان).
این دادهها به شبکههای عصبی عمیق فید میشوند تا پیشبینی کنند که چگونه ترکیبات مختلف اقدامات بالقوه بر مصرف انرژی در آینده تأثیر میگذارند. سپس سیستم هوش مصنوعی اقداماتی را شناسایی میکند که مصرف انرژی را به حداقل میرساند، در حالی که مجموعهای قوی از محدودیتهای ایمنی را نیز برآورده میکند.
اجرای این سیستم کنترل مبتنی بر AI، منجر به کاهش چشمگیر ۴۰ درصدی در انرژی مورد استفاده برای خنکسازی دیتاسنترها شده است، که تقریباً یک کاهش ۱۵ درصدی در PUE کلی را به دنبال دارد. این رویکرد، به گوگل اجازه میدهد تا کارایی عملیاتی را نه به صورت ایستا، بلکه به صورت دینامیک و بر اساس بارهای کاری بلادرنگ تنظیم کند.
در حالی که کارایی PUE به طور قابل توجهی با خنکسازی مایع بهبود یافته و انتشار کربن مرتبط با انرژی سربار کاهش مییابد ، توجه به مصرف آب (معیار Water Usage Effectiveness یا WUE) نیز در بحث پایداری زیرساختهای AI ضروری است.
پیشبینیها نشان میدهند که با گسترش هایپراسکالها و پذیرش سیستمهای خنکسازی مایع، میانگین WUE در حال افزایش است. رویکرد مسئولانه گوگل شامل گزارشدهی شفاف درباره این بدهبستان است.
این شرکت برای دستیابی به پایداری جامع، علاوه بر PUE، معیارهایی مانند WUE و Carbon Usage Effectiveness (CUE) را نیز مدنظر قرار میدهد تا دید کاملتری از عملکرد زیستمحیطی داشته باشد.
تعهد به اولویتبندی مصرف آب مسئولانه، بهینهسازی سیستمهای خنککننده با تعادل بین انرژی، آب و انتشار کربن، و اجرای پروژههای جبران آب در سایتهای جدید ، سطح بالایی از مسئولیتپذیری و تخصص (E-A-T) را در مدیریت پایداری زیرساخت AI در مقیاس جهانی نشان میدهد.
جدول زیر دستاوردهای عملیاتی حاصل از همطراحی زیرساخت TPU و سیستمهای خنکسازی را خلاصه میکند:
| معیار کلیدی | عملکرد ناوگان گوگل (2024) | میانگین صنعت (مرجع) | اثر عملیاتی |
|---|---|---|---|
| PUE (کارایی مصرف برق) | 1.09 | 1.56 | کاهش 84% انرژی سربار نسبت به میانگین صنعت. |
| صرفهجویی AI در خنکسازی | 40% کاهش | N/A | تضمین دمای عملیاتی بهینه با حداقل انرژی توسط DeepMind. |
| چگالی توان رک (AI Cluster) | 80 kW تا 120 kW 28 | 15 kW (سنتی) | ممکن شده توسط استانداردسازی خنکسازی مایع D2C.17 |
| حذف حرارت در منبع (D2C) | 70% تا 75% 17 | N/A | بهبود PUE جزئی و کاهش بار بر زیرساخت تسهیلات. |

TPU Pods هسته مرکزی پلتفرم AI Hypercomputer گوگل را تشکیل میدهند. این پلتفرم نمایانگر یک پشته محاسباتی کاملاً یکپارچه است که در آن تمام اجزا—معماری TPU، شبکه Jupiter/OCS و سیستمهای خنکسازی مایع—به صورت هماهنگ عمل میکنند تا کارایی پیک را برای حجم کاری هوش مصنوعی ارائه دهند.
این رویکرد همطراحی منجر به نتایج ملموس برای کاربران میشود. به عنوان مثال، در مدلهای زبان بزرگ، استفاده از TPU v5p نسبت به TPU v4، منجر به ۲ برابر افزایش سرعت در آموزش شده است.
این بهبودها با غلبه بر تنگناهای سنتی (مانند حرکت داده با MXU و ICI، و قابلیت اطمینان با OCS) و همچنین حفظ دماهای عملیاتی مطلوب از طریق خنکسازی D2C به دست میآید.
TPU Pods در نهایت، مقیاسپذیری و دسترسپذیری مورد نیاز برای آموزش و استنتاج در مدلهای عظیم مانند PaLM و Gemini را فراهم میکنند.
تجربه گوگل با TPU Pods نشان داده است که خنکسازی مایع نه یک گزینه بلکه یک اجبار فیزیکی برای محاسبات با چگالی بالا است.
رهبری گوگل در استقرار D2C، استانداردهای صنعت را تغییر داده است.انتظار میرود که با ادامه افزایش چگالی تراشهها و رکها (که تا ۲۰۰ کیلووات بر رک افزایش مییابد)، خنکسازی D2C (تکفاز) تا سالهای ۲۰۲۵ تا ۲۰۲۶ به جریان اصلی برای حجم کارهای AI تبدیل شود و دوام طولانیمدت زیرساختهای خنکسازی هوا را به چالش بکشد.
این استانداردسازی خنکسازی مایع، یک فشار رقابتی قابل توجهی بر سایر بازیگران حوزه دیتاسنتر ایجاد میکند. بدون اتخاذ راهحلهای پیشرفته مدیریت حرارتی، دستیابی به توانهای محاسباتی Ironwood (با توان ۴۲.۵ ExaFLOPS) در یک فضای فیزیکی محدود دیتاسنتر، عملاً غیرممکن خواهد بود.
تکامل TPU با نسلهای جدید ادامه دارد. معرفی تراشههای آتی مانند Trillium، که ۴.۷ برابر توان محاسباتی پیک بیشتر به ازای هر تراشه و ۶۷ درصد کارایی انرژی بهتری نسبت به نسل قبلی خود ارائه میدهند، تأکید میکند که روند تخصصیسازی و افزایش نیازهای حرارتی ادامه خواهد داشت.
گوگل TPU Pods را نه تنها به عنوان یک شتابدهنده محاسباتی، بلکه به عنوان کاتالیزوری برای معماری مجدد کل دیتاسنتر طراحی کرده است.
همافزایی بین معماری MXU، شبکه OCS که هزاران تراشه را به هم پیوند میدهد، و خنکسازی D2C که چگالی توان را امکانپذیر میسازد، مزیت استراتژیک گوگل در حوزه هوش مصنوعی را در مقیاس عظیم تثبیت میکند و مسیر آینده دیتاسنترهای ابررایانشی پایدار و کارآمد را ترسیم مینماید.
در حالی که هر دو از معماری مشابه (محاسبات موازی) بهره میبرند، دیتاسنترهای هوش مصنوعی تأکید بیشتری بر پایپلاینهای عظیم داده، توان عملیاتی استنتاج (Inference Throughput)، و حاکمیت مدلهای هوش مصنوعی دارند.
HPC اغلب بر شبیهسازیهای علمی و مدلهای ثابت متمرکز است، در حالی که AI DC بر آموزش و بهروزرسانی مداوم مدلهای تریلیون پارامتری تمرکز دارد.
یک دیتاسنتر AI برای تسهیل قابلیتهایی مانند خنکسازی مایع و چگالی توان تا ۱۰۰ کیلووات در هر رک تجهیز میشود، در حالی که رکهای سنتی بین ۳ تا ۱۲ کیلووات توان میکشند.
بله. با توجه به اینکه پردازندههای AI نسل جدید حرارت متمرکز بالایی تولید میکنند و رکها به چگالی بالای ۷۰ کیلووات میرسند، خنکسازی با هوا دیگر کافی نیست.
برای هر مرکزی که به دنبال استقرار GPU/TPU های پرچگالی است،خنکسازی مایع (مانند Direct-to-Chip یا Immersion) از یک گزینه به یک ضرورت عملیاتی و اقتصادی تبدیل شده است.
گوگل از نسل TPU v3 استفاده اجباری از خنکسازی مایع مستقیم به تراشه (D2C) را آغاز کرده است.
به لطف استفاده از تکنولوژیهای پیشرفته خنکسازی مایع و مدیریت هوشمند مبتنی بر هوش مصنوعی (مانند سیستم DeepMind گوگل)، دیتاسنترهای هایپراسکالر AI در تلاشاند تا PUE خود را به زیر ۱.۲ و در حالت ایدهآل بین ۱.۰۷ تا ۱.۱ برسانند.
مدیریت خودکار توسط AI در گوگل نشان داد که میتوان انرژی مصرفی برای خنکسازی را تا ۴۰٪ کاهش داد، که منجر به بهبود PUE کلی حدود ۱۵٪ میشود.
همانطور که بزرگترین بازیگران جهان در حال انتقال از مراکز داده سنتی به "کارخانههای هوش مصنوعی" هستند، دیگر نمیتوان با استفاده از زیرساختهای قدیمی به مزیت رقابتی در حوزه LLMها دست یافت.
ورود به عصر هوش مصنوعی نیازمند بازنگری کامل در معماری زیرساختهای فیزیکی است. اگر سازمان شما در حال برنامهریزی برای استقرار رکهای با چگالی توان ۱۰۰ کیلووات یا بالاتر، طراحی و پیادهسازی سیستم خنکسازی مایع اختصاصی (D2C یا غوطهوری)، یا مهاجرت به معماریهای توان HVDC برای دستیابی به بالاترین PUE و WUE ممکن است، این تصمیمات حیاتی نیازمند مشاوره از معماران زیرساخت با تجربه در مقیاس هایپرمقیاس است.
فیدارکوثر، شریک فنی شما: برای مشاوره تخصصی در زمینه ارزیابی AI-Readiness زیرساخت فعلی، طراحی و استقرار سیستمهای خنکسازی مایع و بهینهسازی معماری توان برای کاهش هزینههای عملیاتی و تضمین پایداری بلندمدت زیرساخت هوش مصنوعی، با تیم متخصصان ما تماس بگیرید. ما به شما کمک میکنیم تا کارخانه هوش مصنوعی خود را با بالاترین راندمان ممکن بسازید.
بعد از ورود به حساب کاربری می توانید دیدگاه خود را ثبت کنید


