
ظهور هوش مصنوعی مولد (Generative AI) و مدلهای بزرگ زبان (LLM)، نقطه عطف جدیدی در مهندسی مراکز داده ایجاد کرده است. امروزه، مراکز داده دیگر صرفاً مخازنی برای ذخیرهسازی دادهها نیستند، بلکه به شتابدهندههایی حیاتی برای نوآوریهای محاسباتی تبدیل شدهاند. طراحی مراکز داده مخصوص هوش مصنوعی نیازمند یک بازنگری کامل در معماری فیزیکی و منطقی است تا بتوانند از پس نیازهای توان، خنکسازی و شبکهسازی خوشههای پردازش موازی برآیند.
زیرساختهای سنتی که برای بارهای کاری CPU-محور و چگالی توان پایین طراحی شده بودند، در مواجهه با تراکم حرارتی سرورهای GPU محور، کاملاً ناکارآمد شدهاند. در این گزارش تخصصی، به بررسی دقیق ستونهای فنی میپردازیم که تضمینکننده طراحی مراکز داده مخصوص هوش مصنوعی با عملکرد بالا، پایداری عملیاتی و کارایی انرژی بینظیر هستند.
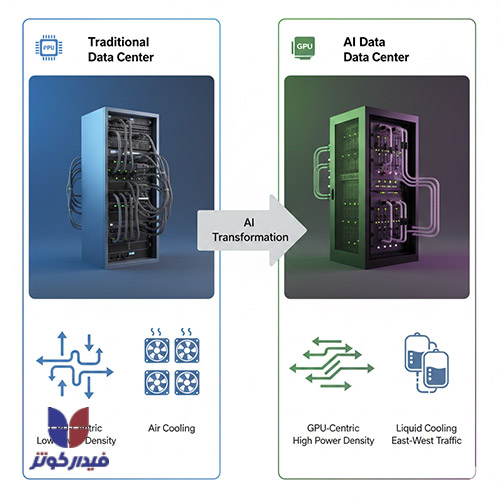
مراکز داده سنتی در دهههای گذشته عمدتاً برای میزبانی از برنامههای کاربردی سازمانی و پردازش عمومی طراحی شده بودند. در این زیرساختها، دادهها بر روی سرورهای سختافزار فیزیکی ذخیره میشوند و مقیاسپذیری منابع معمولاً به دلیل محدودیتهای فیزیکی تجهیزات، امری پرهزینه و زمانبر است.
در مقابل، عصر هوش مصنوعی با معرفی بارهای کاری جدید و سنگین، این معادله را به کلی دگرگون ساخته است. بار کاری هوش مصنوعی، بهخصوص آموزش مدلهای یادگیری عمیق (Deep Learning)، نیازمند قدرت پردازش موازی عظیمی است که عمدتاً توسط واحدهای پردازش گرافیکی (GPU) تأمین میشود.
این وابستگی به GPU و TPUها به عنوان شتابدهندههای محاسباتی، ماهیت مصرف انرژی و تولید گرما در داخل رکها را تغییر داده است. در حالی که دیتاسنترهای سنتی بیشتر بر ذخیرهسازی و پردازش عمومی (CPU-محور) تمرکز داشتند، معماری جدید AI مستلزم یک بازنگری جامع برای مدیریت سه چالش اصلی است: تأمین توان بسیار بالا، دفع حرارت شدید و تضمین تأخیر شبکه بسیار پایین.
این تغییر ماهیت بار کاری، مستقیماً به افزایش تصاعدی چگالی توان رک میانجامد که در ادامه، معماریهای سنتی برق و خنکسازی هوایی را منسوخ و مهاجرت اجباری به فناوریهای پیشرفتهتر را در پی داشته است.علاوه بر این، هوش مصنوعی نقش دوگانه خود را در این اکوسیستم ایفا میکند؛ نه تنها به عنوان مصرفکننده منابع، بلکه به عنوان ابزاری برای بهینهسازی عملیات دیتاسنتر. الگوریتمهای یادگیری ماشین میتوانند در مدیریت انرژی، تنظیم هوشمند سیستمهای خنککننده برای کاهش مصرف برق و پیشبینی خرابی تجهیزات عمل کنند، که این امر به بهبود پایداری و کاهش هزینههای عملیاتی کمک شایانی میکند.
انفجار تقاضای هوش مصنوعی، مراکز داده را به محیطهایی با چگالی فوقالعاده بالا تبدیل کرده است که نیازمند رویکردهای نوین در توزیع و مدیریت توان هستند.
سرورهای GPU که قلب خوشههای هوش مصنوعی را تشکیل میدهند، برای پردازش سریع دادهها به مقادیر زیادی انرژی نیاز دارند. در نتیجه، این سرورها گرمای شدیدی تولید میکنند که سیستمهای خنککننده هوایی سنتی غالباً قادر به کنترل مؤثر آن نیستند. چگالی توان در یک رک معمولی دیتاسنترهای Hyperscale سنتی معمولاً بین ۱۰ تا ۱۴ کیلووات است.
اما در خوشههای محاسبات با عملکرد بالا (HPC) و هوش مصنوعی، این تراکم توان میتواند از ۲۰ تا ۶۰ کیلووات بر رک متغیر باشد. گزارشهای اخیر نشان میدهند که در استقرارهای پیشرفته هوش مصنوعی، چگالی توان حتی به ۸۰ تا ۱۲۰ کیلووات بر رک نیز میرسد. این افزایش شدید چگالی توان یک پیامد فنی مستقیم دارد: تراشههای داخل این سرورها باید در دمای مشخصی نگهداری شوند، در غیر این صورت با نقص عملکرد مواجه شده یا خاموش میشوند.
مطالعه بیشتر: معماری محاسباتی با عملکرد بالا (HPC)
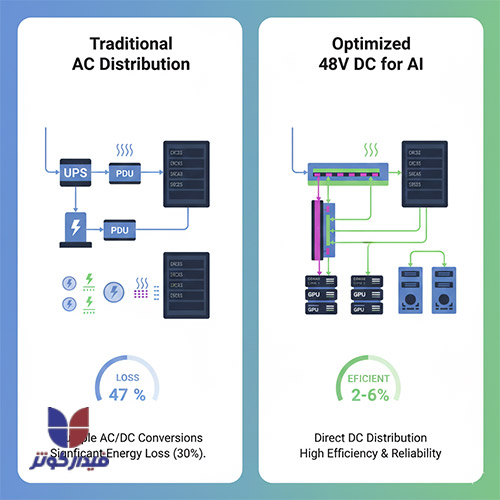
در معماریهای سنتی، سیستمهای برق AC با تلفات انرژی قابل توجهی روبرو هستند. این تلفات ناشی از مراحل متعدد تبدیل است: برق از شبکه اصلی به UPS تبدیل شده، سپس به توزیعکننده و در نهایت در منبع تغذیه سرورها دوباره به DC تبدیل میشود. هر مرحله از این تبدیلها، کسری از توان را به صورت حرارت از دست میدهد.
برای مقابله با این چالش و افزایش کارایی در زیرساختهای پرچگالی AI، توزیع برق ۴۸ ولت DC در سطح رک به یک استاندارد کلیدی تبدیل شده است. این روش با حذف مراحل غیرضروری تبدیل، اتلاف انرژی را تا بیش از ۳۰ درصد کاهش میدهد، که برای سیستمهای با عملکرد بالا و کاهش هزینههای عملیاتی بسیار حیاتی است.
مزیت حیاتی دیگر استفاده از ۴۸ ولت DC، ایمنی است. با وجود اینکه نیازهای توان در حال رشد است، ۴۸ ولت DC همچنان در محدوده ولتاژ فوقالعاده پایین ایمنی (SELV) قرار میگیرد.
این امر در مقایسه با معماریهای ولتاژ بالاتر (مانند ۸۰۰ ولت DC که برخی مقیاسبزرگها در حال بررسی آن هستند)، فرآیندهای ایزولهسازی، حفاظت و صدور گواهینامههای ایمنی را بسیار سادهتر میسازد. پذیرش ۴۸ ولت DC در این شرایط نه تنها یک انتخاب برای افزایش کارایی است، بلکه یک الزام پایداری است که به طور مستقیم به بهبود معیارهای زیستمحیطی کمک میکند، به ویژه در شرایطی که مصرف بالای انرژی توسط مراکز داده در کانون توجه قرار گرفته است.
رکهایی که خوشههای GPU را در خود جای میدهند، باید از نظر فیزیکی با سرورهای سنتی متفاوت باشند. سرورهای GPU، برای فراهم آوردن فضای کافی جهت نصب پردازندههای گرافیکی متعدد و همچنین تامین خنکسازی و توان مورد نیاز، معمولاً در فرم فاکتورهای بزرگتر مانند ۲U یا ۴U عرضه میشوند.
در طراحی مراکز داده مخصوص هوش مصنوعی، رکهای تخصصی (GPU-Optimized) باید الزامات زیر را برآورده کنند:
افزایش چگالی توان در رکهای AI، سیستمهای خنککننده هوا را به نقطه شکست رسانده و مهاجرت به فناوریهای خنکسازی مایع را به امری اجتنابناپذیر تبدیل کرده است.
بارهای کاری هوش مصنوعی گرمای متمرکز و پایداری را تولید میکنند که سیستمهای خنککننده هوایی سنتی قادر به دفع آن نیستند. این ناکارآمدی نه تنها منجر به کاهش عملکرد تراشهها میشود، بلکه ریسک خرابی و خاموشیهای ناگهانی را نیز افزایش میدهد؛ همانند حادثهای که در یکی از بزرگترین اپراتورهای بورس جهان به دلیل نقص در سیستم خنککننده رخ داد.
در مقایسه، مایعات در انتقال حرارت تا سه هزار برابر کارآمدتر از هوا هستند. این راندمان حرارتی فوقالعاده بالا، مایع خنککننده را به تنها راهحل مطمئن برای مدیریت چگالی توان ۱۰۰ کیلووات و بیشتر تبدیل کرده است.
انتخاب راهکار خنکسازی مایع به صورت استراتژیک به سطح چگالی توان مورد نیاز و درجه پیچیدگی معماری دیتاسنتر بستگی دارد. دو فناوری پیشرو در این زمینه عبارتند از خنکسازی مستقیم به تراشه (Direct-to-Chip) و خنکسازی غوطهوری (Immersion Cooling).
مطالعه بیشتر : تکنولوژیهای نوین خنکسازی مایع
در این روش، مایع خنککننده (معمولاً آب یا سیالات تخصصی) از طریق صفحات سرد (Cold Plates) که مستقیماً روی CPU یا GPU قرار میگیرند، عبور میکند. این فرآیند گرمای تولید شده توسط تراشههای اصلی را به صورت هدفمند و با کارایی بالا جذب میکند. DTC مزایای متعددی دارد؛ از جمله سازگاری با معماریهای دیتاسنتر موجود و اغلب اجزای استاندارد سختافزاری.
با این حال، DTC عمدتاً تراشههای اصلی را خنک میکند و اجزای محیطی مانند ماژولهای حافظه، هارد دیسکها و منابع تغذیه درون رک، همچنان ممکن است به نوعی خنکسازی ثانویه (معمولاً هوا) نیاز داشته باشند.
خنکسازی غوطهوری شامل قرار دادن کامل سختافزار، از جمله مادربردها و قطعات، در یک سیال دیالکتریک (غیررسانا) مانند ۳M Novec یا Fluorinert است. این روش بالاترین کارایی حرارتی را به ارمغان میآورد زیرا گرما به صورت یکنواخت از کل سطح برد و تمام اجزا دفع میشود. این سیستمها فنهای داخلی را حذف کرده و نویز عملیاتی را به شدت کاهش میدهند.
خنکسازی غوطهوری برای دستیابی به چگالی توان بسیار بالا (۱۰۰ کیلووات و بیشتر) و بهترین PUE ممکن، ایدهآل است. اگرچه هزینه اولیه بالاتری دارد و نیاز به مدیریت مایعات تخصصی دارد، اما راندمان کلی سیستم را به میزان قابل توجهی افزایش میدهد. مقایسه ویژگیهای کلیدی این دو روش در جدول زیر آمده است:
| ویژگی | خنکسازی مستقیم به تراشه (DTC) | خنکسازی مایع غوطهوری (Immersion) |
|---|---|---|
| روش خنکسازی | تماس مستقیم مایع با صفحات سرد CPU/GPU | غوطهوری کامل سختافزار در سیال دیالکتریک |
| دفع گرما | هدفمند، عمدتاً CPU و GPU | یکنواخت، دفع گرمای کل برد |
| PUE هدف | قابل دستیابی به زیر 1.3 | هدفمند برای زیر 1.2 (سطح Hyperscale) |
| پیچیدگی سیستم | نصب و نگهداری پیچیدهتر، احتمال نشت | زیرساخت خنککننده سادهتر، نیاز به مخزن و سیال |
| مناسب برای تراکم | بالا (تا ۶۰ کیلووات بر رک) | بسیار بالا (تا ۱۲۰ کیلووات بر رک) |
اثربخشی مصرف برق (PUE) معیار حیاتی برای سنجش کارایی عملیاتی دیتاسنتر است. در حالی که مراکز داده سنتی هوا خنک اغلب PUE در محدوده $1.4$ تا $1.6$ دارند، مراکز داده هوش مصنوعی نسل جدید به دنبال دستیابی به PUE بسیار پایینتر هستند. مراکز داده Hyperscale AI که از خنکسازی مایع استفاده میکنند، PUEهایی زیر $1.3$ و در استقرارهای پیشرفتهتر زیر $1.2$ را هدف قرار میدهند.
این راندمان بالا برای برآورده کردن تعهدات پایداری Hyperscalerها حیاتی است. کاهش PUE همچنین ارتباط مستقیمی با مدیریت آب دارد.مهاجرت به سیستمهای خنکسازی مایع بسته، نیاز به استفاده از برجهای خنککننده سنتی مبتنی بر آب را که آب زیادی مصرف میکنند، از بین میبرد.
بسیاری از شرکتهای پیشرو متعهد شدهاند که در مناطق کمآب از این برجها استفاده نکنند. به عنوان مثال، مایکروسافت طرحهایی را برای مراکز دادهای معرفی کرده است که آب جدیدی مصرف نمیکنند و از آب در یک چرخه بسته بین سرورها و سردکنها استفاده میکنند.
این موضوع نشان میدهد که در طراحی دیتاسنتر AI، ملاحظات زیستمحیطی (مانند مصرف آب) اکنون به عنوان فاکتورهای تعیینکننده مکانیابی و طراحی زیرساخت عمل میکنند. علاوه بر این، استفاده از خود هوش مصنوعی برای مدیریت زیرساخت (AI-Powered Management) میتواند با بهینهسازی توزیع بار و سیستمهای تهویه، مصرف کلی انرژی را تا ۲۰ تا ۳۰ درصد کاهش دهد که به طور مستقیم PUE هدف را بهبود میبخشد.
مطالعه بیشتر : بهینهسازی کارایی مصرف توان (PUE)

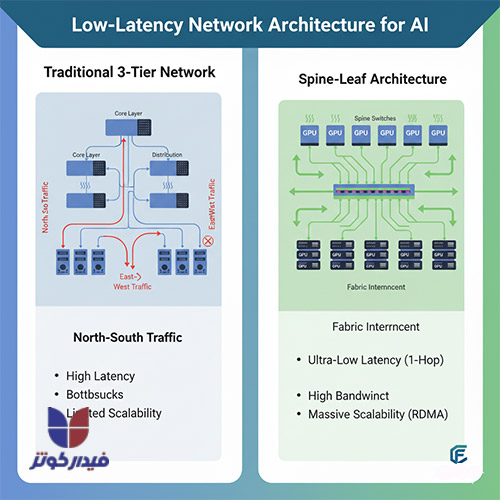
چالش دوم در طراحی مراکز داده مخصوص هوش مصنوعی، تضمین سرعت و پهنای باند لازم برای همگامسازی هزاران پردازنده با تأخیر کم است.
در زیرساختهای سنتی، ترافیک غالب به صورت شمالی-جنوبی (بین کلاینت و سرور) جریان داشت. اما در خوشههای هوش مصنوعی، به دلیل ماهیت پردازش موازی، حجم عظیمی از دادهها باید به سرعت و به صورت مستمر بین سرورها و GPUها جابجا شود. این امر منجر به دامیننس شدید ترافیک شرقی-غربی (سرور به سرور) شده است.
برای جلوگیری از تبدیل شدن شبکه به گلوگاه عملکردی در آموزش مدلها، ارتقاء زیرساخت شبکه به سطوح بسیار بالاتر از استانداردهای گذشته الزامی است. این زیرساخت باید از شبکههای پرسرعت ۲۰۰، ۴۰۰ و حتی ۸۰۰ گیگابیت بر ثانیه پشتیبانی کند. در این زمینه، فیبر نوری با توانایی انتقال داده تا چندین ترابایت در ثانیه و کاهش تأخیر به زیر میکروثانیه، تنها گزینه قابل اتکا برای پشتیبانی از پروتکلهای ۴۰۰G و ۸۰۰G در این زیرساختها محسوب میشود.
اگر شبکه از نوع قدیمی (Top-of-Rack) باشد و از فناوریهایی مانند RDMA (دسترسی مستقیم از راه دور به حافظه) پشتیبانی نکند، عملکرد مدل دچار افت محسوسی خواهد شد.
برای مدیریت ترافیک East-West، معماری شبکههای مرکز داده باید از مدل سنتی سه لایه به معماری Spine-Leaf (ستون فقرات-برگ) مهاجرت کند. در معماری Spine-Leaf، هر سوئیچ Leaf (که به سرورها متصل است) به هر سوئیچ Spine متصل میشود.
این ساختار تضمین میکند که هر ارتباطی در شبکه تنها از طریق حداکثر یک هاپ (Hop) انجام شود. مزایای این معماری برای زیرساخت هوش مصنوعی بسیار حیاتی است:
انتخاب پروتکل اتصال داخلی در خوشههای GPU (Fabric Interconnect) یک تصمیم استراتژیک است که بر عملکرد، هزینه و مقیاسپذیری دیتاسنتر AI تأثیر میگذارد. دو فناوری اصلی در این زمینه InfiniBand و RoCE v2 هستند:
InfiniBand یک اتصال اختصاصی است که ذاتاً بدون اتلاف (Lossless) بوده و دارای کنترل جریان قطعی (Deterministic Flow Control) است. مزیت اصلی آن، تأخیر فوقالعاده کم و قابل پیشبینی است.
به همین دلیل، InfiniBand ایدهآل برای بارهای کاری HPC علمی و آموزش مدلهای AI با همگامسازی بسیار دقیق است. با این حال، تجهیزات InfiniBand معمولاً گرانتر هستند و نیازمند تخصص عملیاتی ویژه هستند.
RoCE v2 فناوری RDMA (دسترسی مستقیم از راه دور به حافظه) را روی زیرساخت استاندارد اترنت فعال میکند. این امر به دیتاسنترها امکان میدهد از تجهیزات استاندارد اترنت استفاده کنند و به کاهش هزینههای مالکیت (TCO) بین ۴۰ تا ۵۵ درصد نسبت به شبکههای اختصاصی InfiniBand منجر میشود.
RoCE v2 برای محیطهای Hyperscale و ابری که نیاز به مقیاسپذیری به هزاران نود دارند، بسیار مناسب است.هرچند RoCE v2 میتواند به تأخیر پایین نزدیک به IB دست یابد، اما این امر مستلزم تنظیمات بسیار دقیق کنترل ازدحام، مدیریت صف و مهارت عملیاتی بالای پرسنل شبکه است. انتخاب بین این دو فناوری به عوامل متعددی بستگی دارد که در جدول زیر به طور خلاصه آمده است:
| معیار | InfiniBand (IB) | RoCE v2 (RDMA over Ethernet) |
|---|---|---|
| معماری اصلی | اختصاصی، بدون اتلاف، کنترل جریان قطعی | مبتنی بر اترنت استاندارد IP |
| تأخیر | فوقالعاده کم و قابل پیشبینی | مشابه IB (با تنظیم دقیق)، اما وابسته به مهارت اپراتور |
| هزینه مالکیت (TCO) | بالاتر | ۴۰ تا ۵۵٪ کاهش هزینه |
| مقیاسپذیری | بهینه برای خوشههای کوچک تا متوسط | عالی برای محیطهای ابری Hyperscale با هزاران نود |
| بهترین کاربرد | آموزش متمرکز و HPC علمی | محیطهای الاستیک، کلود و حساس به هزینه |
با ادامه رشد تراکم توان رک، اتصالات الکتریکی مسی در داخل رک و سیستم به سرعت با محدودیتهای توان و حرارت مواجه میشوند. برای غلبه بر این مانع فیزیکی، فناوری اپتیکهای همبسته (CPO) در حال ظهور است. CPO شامل قرار دادن قطعات نوری مستقیماً در کنار تراشه پردازش (GPU/XPU) یا سوئیچ ASIC است.
این نزدیکی فیزیکی فاصله طی شده توسط سیگنالهای الکتریکی قبل از تبدیل به نور را به شدت کاهش میدهد. در نتیجه، CPO مصرف توان، تلفات سیگنال و تأخیر ارتباطی را به میزان چشمگیری کاهش میدهد و پهنای باند و سرعت را افزایش میبخشد.
CPO به عنوان یک فناوری فعالکننده، برای معماریهای چند رک که نیاز به ارتباطات نوری با توان مصرفی کم و پایداری حرارتی بالا دارند، یک ضرورت محسوب میشود و زمینه را برای همگرایی نهایی شبکههای HPC و کلود فراهم میکند.
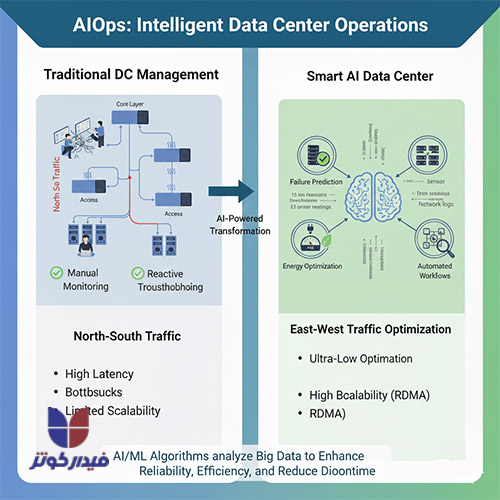
مراکز داده هوش مصنوعی صرفاً مجموعهای از سختافزارهای پرچگالی نیستند، بلکه نیازمند عملیات هوشمند، انعطافپذیری در استقرار و حفاظت شدید از داراییهای دادهای هستند.
مدیریت مراکز دادهای که چگالی توان بسیار بالایی دارند و حیاتی هستند، بدون اتوماسیون هوشمند عملاً غیرممکن است. AIOps (هوش مصنوعی برای عملیات فناوری اطلاعات) با بهرهگیری از یادگیری ماشین و کلان دادهها، قابلیتهای مدیریتی را به سطح جدیدی ارتقا میدهد.
AIOps با تحلیل لحظهای حجم وسیعی از دادهها (شامل گزارشهای سیستم، دادههای سنسورها و جریانهای شبکه)، الگوها و ناهنجاریهایی را شناسایی میکند که ممکن است توسط تیمهای انسانی نادیده گرفته شوند. کاربردهای کلیدی AIOps در محیط دیتاسنتر AI شامل موارد زیر است:
با توجه به تغییرات سریع در فناوریهای هوش مصنوعی و نیازهای متغیر در مقیاسپذیری، ماژولار بودن در طراحی دیتاسنتر AI از اهمیت بالایی برخوردار است. مراکز داده ماژولار (مانند طرحهای کانتینری یا پیشساخته) امکان پیکربندی مجدد و سفارشیسازی آسان اجزایی مانند سیستمهای سرمایشی، GPUها و منابع تغذیه را فراهم میآورند. مزایای اصلی این رویکرد عبارتند از:
مدلهای هوش مصنوعی و دادههای آموزشی آنها از ارزشمندترین داراییهای یک سازمان محسوب میشوند و حفاظت از این مالکیت فکری (IP) حیاتی است. طراحی دیتاسنتر AI باید شامل الزامات امنیتی دوگانه باشد: فیزیکی و سایبری.
امنیت فیزیکی: باید استانداردهای بالای امنیتی در مکانیابی دیتاسنتر رعایت شود. این الزامات شامل اجرای دقیق سیستمهای کنترل دسترسی تردد (Biometric/Card Access) و مانیتورینگ ۲۴ ساعته توسط دوربینهای کنترلی است. علاوه بر این، باید مقاومت ساختاری در برابر عوامل طبیعی و حریق (نصب درب ضدحریق، سیستمهای اطفاء حریق درون رکها) رعایت شود. انطباق کامل با استانداردهای بینالمللی مانند TIA-942 و ISO/IEC 27001 در این زمینه، نه تنها امنیت را تضمین میکند، بلکه اخذ مجوزها و ممیزیهای ضروری را تسهیل مینماید.
امنیت منطقی و سایبری: زیرساختهای AI هدف حملات سایبری گسترده هستند. سیستمهای مبتنی بر یادگیری ماشین میتوانند به عنوان یک لایه دفاعی اضافی عمل کنند. هوش مصنوعی با تجزیه و تحلیل الگوهای شبکه و دادهها، قابلیت نظارت بر شبکه و شناسایی و پیشگیری از حملات و نقصهای امنیتی را داراست. این قابلیتها برای حفاظت از خوشههای پرچگالی و دادههای حساس مدلهای AI ضروری است.
س: چالش اصلی در طراحی مراکز داده مخصوص هوش مصنوعی چیست؟
پاسخ: چالش اصلی، مدیریت چگالی توان بیسابقه ناشی از خوشههای GPU است که میتواند از ۱۰ کیلووات به بیش از ۶۰ تا ۱۰۰ کیلووات بر رک افزایش یابد. دفع گرمای حاصل از این توان بالا نیازمند انتقال اجباری از خنکسازی هوایی به خنکسازی مایع (مانند DTC یا غوطهوری) و بازنگری کامل در زیرساخت توزیع برق و شبکه با تأخیر کم است.
س: بهترین معیار PUE برای مراکز دادهای که از خنکسازی مایع استفاده میکنند، چقدر است؟
پاسخ: مراکز داده Hyperscale AI که از خنکسازی مایع استفاده میکنند، PUEهایی زیر $1.3$ و در بسیاری از موارد زیر $1.2$ را هدف قرار میدهند. این راندمان به دلیل کارایی حرارتی بسیار بالاتر مایعات است و برای دستیابی به پایداری عملیاتی و رعایت تعهدات زیستمحیطی حیاتی است.
س: تفاوت اصلی خنکسازی Direct-to-Chip و Immersion Cooling چیست؟
پاسخ:
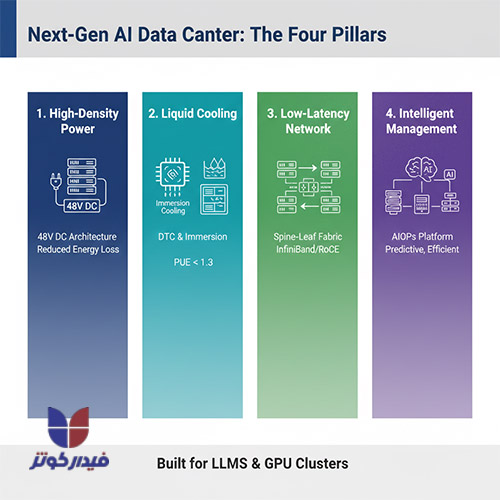
طراحی مراکز داده مخصوص هوش مصنوعی نه تنها یک ارتقاء سطحی، بلکه یک جهش بنیادی در مهندسی زیرساخت محسوب میشود. زیرساختهای سنتی توانایی پشتیبانی از الزامات محاسباتی LLMها و خوشههای GPU را ندارند. موفقیت در ساخت و عملیات مراکز داده AI مستلزم اجرای همزمان چهار رکن اصلی است:
نادیده گرفتن هر یک از این ارکان، به صورت زنجیرهای به گلوگاههای عملکردی در آموزش مدلها، افزایش هزینههای عملیاتی و شکست در دستیابی به اهداف پایداری منجر خواهد شد. دیتاسنترهای AI، زیرساختهایی هستند که مرز بین معماری سنتی و آینده محاسبات را ترسیم میکنند.
بعد از ورود به حساب کاربری می توانید دیدگاه خود را ثبت کنید



